T-Mobile’s message dispatcher m14262a() receives the request from InstallerHelper, classifies the message based on message.what message type, and routes the message accordingly:
Next handlerParams.startInstall() calls prepareInstall(), which in turn calls performInstallBundle():
public boolean startInstall(@NotNull ServiceHandler handler) {
Intrinsics.checkNotNullParameter(handler, "handler");
int prepareInstall = prepareInstall(handler);
...
public int prepareInstall(@NotNull ServiceHandler handler) {
...
return performInstallBundle(handler.getMContext());
}
Then performInstallBundle() passes execution to InstallParams method m14247a():
public final int performInstallBundle(@NotNull Context context) {
…
int m14247a = m14247a(context, "", arrayList, false);
Finally, m14247a tells the Android Package Manager to perform the install:
//pass install to Android Package Manager
public final int m14247a(Context context, String str, ArrayList arrayList, boolean z6) throws Throwable {
PackageInstaller packageInstaller = context.getPackageManager().getPackageInstaller();
...
PackageInstaller.SessionParams sessionParams = new PackageInstaller.SessionParams(this.mInstallSessionMode);
sessionParams.setAppLabel(getAppName(context));
sessionParams.setAppPackageName(getCom.google.firebase.remoteconfig.RemoteConfigConstants.RequestFieldKey.PACKAGE_NAME java.lang.String());
...
setMInstallerSessionId$app_currentRelease(packageInstaller.createSession(sessionParams));
...
this.f33245C = packageInstaller.openSession(getMInstallerSessionId());
Iterator it = arrayList.iterator();
Intrinsics.checkNotNullExpressionValue(it, "iterator(...)");
int iM14248c2 = -999;
while (it.hasNext()) {
Object next = it.next();
Intrinsics.checkNotNullExpressionValue(next, "next(...)");
Timber.INSTANCE.getClass();
iM14248c2 = m14248c((String) next);
if (1 != iM14248c2) {
break;
}
}
...
Intent intent = new Intent(context, (Class<?>) InternalReceiver.class);
intent.setAction(InternalReceiver.ACTION_INSTALLER_RESULT);
PendingIntent broadcast = PendingIntent.getBroadcast(context, 0, intent, Build.VERSION.SDK_INT >= 31 ? 167772160 : 134217728);
PackageInstaller.Session session = this.f33245C;
if (session != null) {
session.commit(broadcast.getIntentSender());
}
AppHub uses a variety of installers with heightened privileges from manufacturer or carrier
The preceding section discusses AppHub passing execution to T-Mobile InstallerHelper. But consider devices that don’t have T-Mobile InstallerHelper. AppHub code shows AppLovin also using other install helpers from other manufacturers and carriers.
T-Mobile and Sprint
public final InstallerHelperResult bindToInstaller(boolean useForegroundServiceIfNeeded) {
...
PackageManager.PackageInfoFlags of;
PackageManager.PackageInfoFlags of2;
PackageManager.ResolveInfoFlags of3;
if (isReady()) {
if (this.f19986b) {
Log.e("CM_TMO_SDK", "Binding failed, service already bound");
}
return new InstallerHelperResult.Fail(ConstantsKt.ERROR_KEY_ALREADY_BOUND, null);
}
if (((Number) this.f19989e.getValue()).intValue() < 3000) {
return new InstallerHelperResult.Fail(ConstantsKt.ERROR_KEY_VERSION_NOT_SUPPORTED, null);
}
String str = "com.tmobile.dm.cm.extra.PACKAGE_NAME";
String str2 = "com.tmobile.dm.cm.extra.APP_LABEL";
if (AbstractC0945q.m2146P((String) this.f19987c.getValue(), "com.tmobile.dm.cm.permission.UPDATES_INSTALL", false)) {
intent = new Intent("com.tmobile.action.INSTALLER_SERVICE");
} else if (AbstractC0945q.m2146P((String) this.f19987c.getValue(), "com.tmobile.dm.cm.permission.TRUSTED_UPDATES_INSTALL", false)) {
intent = new Intent("com.tmobile.action.INSTALLER_TRUSTED_SERVICE");
} else {
str = "com.sprint.ce.updater.extra.PACKAGE_NAME";
str2 = "com.sprint.ce.updater.extra.APP_LABEL";
if (AbstractC0945q.m2146P((String) this.f19987c.getValue(), "com.sprint.permission.INSTALL_UPDATES", false)) {
intent = new Intent("com.sprint.action.INSTALLER_SERVICE");
} else {
if (!AbstractC0945q.m2146P((String) this.f19987c.getValue(), "com.sprint.ce.updater.permission.TRUSTED_INSTALL_UPDATES", false)) {
return new InstallerHelperResult.Fail(ConstantsKt.ERROR_KEY_PERMISSION_SECURITY_ISSUE, null);
}
intent = new Intent("com.sprint.action.INSTALLER_TRUSTED_SERVICE");
...
Some versions of AppHub reference com.applovin.oem.p036am.device.realme.RealmeDownloader, which through its name indicates that it is a Realme library to perform downloads.
In AppHub code, I found references to Cricket, Oppo, Orange, Sliide, Tinno. But I didn’t see full installation integrations for these carriers within the AppHub versions I received. That said, it seems AppLovin provides a different AppHub APK for each partner. When I bought a device from T-Mobile, I naturally received a phone with the T-Mobile AppHub APK. The lack of other carriers’ AppHub APKs on a T-Mobile device should not be seen as a surprise.
An AppLovin press release describes a partnership with OPPO for “mobile app recommendations that “connect[] users with a wide variety of apps, from popular games to productivity tools, designed to cater to the unique preferences of each user.” This could be a euphemism for installing games when users merely view ads for those apps.
Xiaomi and TCL
The Culper report discusses AppLovin AppHub partnerships with Xiaomi and TCL. I did not find evidence of integration between AppHub and these companies in the code I reviewed. Here too, there could be other APK versions that implement these integrations.
In DirectDownloadActivity, I presented code in which execution flows to DirectDownloadMainFragment C3374l2. Then C3374l2’s constructor creates C3298a3:
The WebViewClient C4785e() constructor prepares the web view. Where a response includes references to resources in com.applovin.array.resources, or otherwise within the arrayList2 list, local resource interception substitutes resources from the APK’s Resources folder.
The most important local resource is app\src\main\assets\directdownload-ui\assets\index-BFfWBgBF.js, a substantial block of minified JavaScript which is 13,069 lines long after pretty-printing.
Among other tasks, this file parses a server response to create what it calls a mergedConfig which determines what settings to use for the possible installation. These settings include “IsAutoInstall”, which is set based on what is received from the server, potentially supplemented by a default value from a local data structure called wt.
function Op(e, t) { //check whether isAutoInstallEnabled
return e ? e.toLowerCase() === pr : t ? t.toLowerCase() === pr : wt.isAutoInstallEnabled
}
const ...
s = t[Ct.IsAutoInstallEnabled],
o = t[Ct.IsAutoInstallEnabledOld], ...
return {...
isAutoInstallEnabled: Op(s, o), ...
If isAutoInstall is set to true, then the JavaScript installs the app immediately:
Wt(() => {
(async () => {
...
const R = We(Qc);
if (!(!t.viewModel.isFirstLoad || !t.viewModel.isAutoInstall || R)) {
if (t.viewModel.autoInstallDelayMs <= 0) {
c();
return
...
The JavaScript function c()proceeds with installation, passing execution to installApp():
async function c() { //run the install
...
message: "App download and install start"
...
M = await Ge.installApp(t.viewModel.packageName, t.viewModel.versionCode, t.adToken)
The installApp() function relies on a constant specifying the endpoint destination:
me = (e => (... e.InstallApp = "install-app" ...
The installApp() function calls that endpoint:
async installApp(t, r, n) { //bridge back to Java code
pe.leaveBreadcrumb({message: `Native method "${me.InstallApp}" call`});
const a = (o=this.xhrUrls)==null ? void 0 : o[me.InstallApp];
const s = await this.nativeXhrClient.makeNativeXhrRequest({
xhrUrl: a,
body: Ia({packageName: t, versionCode: r, adToken: n})
});
return this.unwrapNativeAppResponse(s.dataText, me.InstallApp);
}
The function makeNativeXhrRequest wraps the custom httpClient.makeHttpRequest which in turn wraps the standard XMLHttpRequest, which finally calls the endpoint:
async makeNativeXhrRequest(t) {
const {body: r, headers: n, httpMethod: a = nt.Post, queryParams: s, shouldStartSpan: o, spanAttributes: d, xhrUrl: f} = t;
...
return await this.httpClient.makeHttpRequest(v);
class Hh {
makeHttpRequest(t) {
...
return new Promise((o, d) => {
const f = new XMLHttpRequest;
...
f.send(s);
Installation On Close
The preceding section explores JavaScript logic under the isAutoInstall configuration, which causes an immediate installation. But adjacent JavaScript code offers two other ways installations can proceed automatically (and still without user consent despite, in these paths, an installation screen briefly presented to the user): What the code calls “Install On Close”, and installation after a brief countdown. Key lines from the JavaScript setup that considers these possibilities:
If isOneClickInstallOnCloseEnabled, the JavaScript installs the app when the user closes the ad, also using the c() function. First, JavaScript subscribes function C() to listen for events named “native-cross-button-custom-behavior”:
function A() {
Bo.setDispatchEventBehavior()
}
Wt(() => {
Bo.setChannel((...U) => Ge.setNativeCrossButtonBehavior(...U));
const M = Yp.subscribe(C),
R = wi(A, 10),
F = Ce.topOpened.subscribe(R);
return () => (M(), F()) ...
As a result, C() runs when the user taps the x button to close the screen proposing to install an app.
Then C() forms variable F to indicate whether installs on close are disabled, and variable U to indicate whether the timer is running. If either is true, tapping X simply closes the screen (via the return line in red below). (Of course if the timer is running, installation will still proceed in due course, as detailed in the next section.) But if both are false (installs on close is enabled, and timer is not running), then the code proceeds with installation. In particular, C() then logs this event as “Installation on ‘x’ button click”, and executes function c() to proceed with installation.
function C(M) {
if (!M) return;
if (We(Ce.topOpened)) return void Ce.closeTop();
const F = We(Dr).isOneClickInstallOnCloseEnabled, U = We(f).isRunning;
if (!F || !U) {
...
return
}
pe.leaveBreadcrumb({
message: 'Installation on "X" button click',
metadata: {
isOneClickInstallOnCloseEnabled: F
},
type: "manual"
}), c(), ie.reportEvent(he.UiNativeCrossButtonClick, {
isOneClickInstallOnCloseEnabled: F,
isTimerActive: U,
shouldStartAutoInstall: !0
}), Pn(100).then(() => {
Ge.closeUiOnNativeCrossButtonClick()
})
Installation via Countdown
Alternatively, the JavaScript sets up a timer called f to count down from the number of milliseconds specified in autoInstallDelayMs:
The default starting value of the timer is 5e3, i.e. 5×103=5000 milliseconds=5 seconds.
const wt = {
...
autoInstallDelayMs: 5e3, ...
The timer’s onExpire event is set to trigger installing the app, again via the c() function:
function av(e, t) {
var N;
be(t, !0);
const [r, n] = st(), a = () => ke(Nr, "$installationStateControlledStore", r), s = () => ke(f, "$timer", r);
let o = He(gt(((N = a()) == null ? void 0 : N.status) ?? null)),
d = He(!1);
const f = rv({
...
onExpire: () => {
ie.reportEvent(he.AppAutoInstallTimerEnd), c()
...
As the timer counts down, it updates an on-screen label with the number of seconds left. First, the code creates a string Ku for the label template, with a placeholder {secondsCountdown} to be replaced by the current remaining time:
Ku = "Install in {secondsCountdown}s",
Then, a reactive state accessor r binds to the timer, running every 100ms:
const [r, n] = st(), a = () => ke(Nr, "$installationStateControlledStore", r), s = () => ke(f, "$timer", r);
...
tickIntervalMs: t = 100, ...
At the tickInterval, the reactive computation z() checks the currentMs left on the timer, storing this in variable i:
const ev = 1e3;
...
let i = z(() => s().isExpired || s().isAborted || !s().isRunning ? null : Math.ceil(s().currentMs / ev));
The reactive data exposure declares property secondsCountdown to be equal to i:
secondsCountdown: w(i),
The function w() evaluates the reactive computation and returns its current value, in turn updating the UI:
function w(e) {
...
return r && (a = e, zn(a) && zl(a)), Hn && En.has(e) ? En.get(e) : e.v
Then the reactive UI updates the displayed value, running the standard JavaScript replace method to find the placeholder {secondscountdown} and substitute the current value of secondsCountdown.
let c = z(() => !t.wasAutoInstallCancelled && typeof t.secondsCountdown == "number"),
h = z(() => t.installationStatus === Xe.Downloading || t.installationStatus === Xe.Installing),
v = z(() => t.installationStatus === Xe.Installed),
_ = z(() => {
if (w(c)) return a()[V.InstallIn].replace("{secondsCountdown}", `${t.secondsCountdown}`);
The net effect is a simple countdown timer, albeit with the unusual characteristic of showing labels like “Install in 3s” (with the letter “s” denoting seconds, and with no space between the number and the units). Notably, this “Install in 3s” format exactly matches the display one user preserved in a video, and another in a screenshot.
Then c3359j1 continuation entry point mo410r() passes execution to DirectDownloadMainFragment C3374l2:
public final Object mo410r(Object obj) {
...
AbstractC0419z0 supportFragmentManager = directDownloadActivity3.getSupportFragmentManager();
C0346a c0346a = new C0346a(supportFragmentManager);
c0346a.f1416q = true;
c0346a.m1138j(C3374l2.class, "com.applovin.array.directdownload.DirectDownloadActivity.TAG.DirectDownloadMainFragment");
...
C3374l2.mo1147B(), the obfuscated version of onViewCreated, launches a coroutine C3339g2:
public final void mo1147B(View view, Bundle bundle) { //WebView loader
...
super.mo1147B(view, bundle);
AbstractC1838d0.m3857y(AbstractC1150s0.m2348e(m1163h()), null, null, new C3360j2(this, null), 3);
AbstractC1838d0.m3857y(AbstractC1150s0.m2348e(m1163h()), null, null, new C3339g2(this, null), 3);
}
C3374l2’s parent class is AbstractC3404p4, so the reference to super.mo1147B() passes execution to AbstractC3404p4.mo1147B() which creates a WebView and configures its settings and permissions:
Return to C3374l2.mo1147B() (one step above) and notice that it also creates a new C3339g2. C3339g2 in turn passes execution to C3332f2 continuation entry point mo410r() and then to C3325e2 continuation entry point mo410r():
public final Object mo410r(Object obj) {
...
AbstractC6434a.m9578e(obj);
EnumC1139n enumC1139n = EnumC1139n.f3808u;
C3374l2 c3374l2 = this.f10528x;
C3332f2 c3332f2 = new C3332f2(c3374l2, null);
this.f10527w = 1;
...
public final Object mo410r(Object obj) {
...
AbstractC6434a.m9578e(obj);
C3374l2 c3374l2 = this.f10513x;
InterfaceC2618h m4562l = AbstractC2611e1.m4562l(new C2627k(6, new C1739h(c3374l2.mo5736N().f10412w, 1)));
C3325e2 c3325e2 = new C3325e2(c3374l2, null);
this.f10512w = 1;
...
((C2638n1) interfaceC2664x0).m4576l(obj);
...
Then C3325e2 continuation entry point mo410(r) calls coroutine continuation orchestrator m5734P to load the WebView:
public final Object mo410r(Object obj) {
...
obj = C3374l2.m5734P(c3374l2, c1059xM2213d, c0857r, this);
m5734P calls m5748L to get the URL to be loaded into the WebView.
public static final Comparable m5734P(C3374l2 c3374l2, C1059x c1059x, C0857r c0857r, AbstractC1576c abstractC1576c) {
...
objM5738Q = c3374l2.m5738Q(c0857r, c1059x, c3297a2);
return c3374l2.m5748L((C3447v5) objM5738Q);
...
public final Uri m5748L(C3447v5 c3447v5) { //Create URI with configuration
Uri.Builder buildUpon = C4785e.f14377e.buildUpon();
byte[] bytes = c6488c.m9632c(C3447v5.Companion.serializer(), c3447v5).getBytes(C0929a.f3221a);
String encodeToString = Base64.encodeToString(bytes, 11);
Uri build = buildUpon.fragment(encodeToString).build();
return build;
}
Return to AbstractC3404p4.mo1147B(), two steps above. Notice that it also creates C3334f4, whose continuation entry point mo410(r) passes execution to C3320d4:
public final Object mo410r(Object obj) {
...
C3320d4 c3320d4 = new C3320d4(abstractC3404p4, c4236u, this.f10508y, null);
Then C3320d4 continuation entry point mo410r() loads the specified URL into the WebView
public final Object mo410r(Object obj) { //WebView loader - actually loads the WebView
WebView webView;
Uri uri;
EnumC1084a enumC1084a = EnumC1084a.f3658a;
int i = this.f10487x;
WebView webView2 = this.f10485B;
AbstractC3404p4 abstractC3404p4 = this.f10489z;
if (i == 0) {
AbstractC6434a.m9578e(obj);
Uri uri2 = (Uri) this.f10488y;
C1057v c1057vM687d0 = AbstractC0192d0.m687d0(abstractC3404p4.f10704p0);
C1036f0 c1036f0 = C1036f0.f3471c;
C1059x c1059xM2213d = C1043j.m2213d(AbstractC4118e.m6295A(abstractC3404p4).f12547o, "DDWebViewPageLoad", c1057vM687d0, AbstractC1499w3.m3259C().m2211a(new C1030c0(abstractC3404p4.f10708t0)), 8);
C4236u c4236u = this.f10484A;
InterfaceC1843e1 interfaceC1843e1 = (InterfaceC1843e1) c4236u.f12868a;
if (interfaceC1843e1 != null) {
interfaceC1843e1.mo3869d(null);
}
c4236u.f12868a = AbstractC1838d0.m3857y(AbstractC1150s0.m2348e(abstractC3404p4.m1163h()), null, null, new C3397o4(abstractC3404p4, c1059xM2213d, null), 3);
C1854h0 c1854h0 = abstractC3404p4.mo5736N().f10646m;
this.f10488y = uri2;
this.f10486w = webView2;
this.f10487x = 1;
Object objM3951z = c1854h0.m3951z(this);
if (objM3951z == enumC1084a) {
return enumC1084a;
}
webView = webView2;
obj = objM3951z;
uri = uri2;
} else {
if (i != 1) {
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
webView = this.f10486w;
uri = (Uri) this.f10488y;
AbstractC6434a.m9578e(obj);
}
webView.setWebViewClient((WebViewClient) obj);
webView2.loadUrl(uri.toString());
abstractC3404p4.mo5736N().f10649p = true;
AbstractC3305b3.f10440a.m2458q("WebView::loadUrl", new Object[0]);
return C6458y.f19392a;
Receiving 6 as its first parameter, AppHub’s onTransact() selects the corresponding case of the switch, passing execution to AppHub’s showDirectDownloadAppDetailsWithExtra().
public boolean onTransact(int i, Parcel parcel, Parcel parcel2, int i2) throws RemoteException {
...
switch (i) {
...
case 6:
showDirectDownloadAppDetailsWithExtra(parcel.readString(), (Bundle) _Parcel.readTypedObject(parcel, Bundle.CREATOR), IAppHubDirectDownloadServiceCallback.Stub.asInterface(parcel.readStrongBinder()));
return true;
case 7:
directInstall(parcel.readString(), (Bundle) _Parcel.readTypedObject(parcel, Bundle.CREATOR), IAppHubDirectDownloadServiceCallback.Stub.asInterface(parcel.readStrongBinder()));
return true; ...
Next, showDirectDownloadAppDetailsWithExtra() passes execution to service method AbstractC1838d0.m3826C() with delegate C2823r for asynchronous processing.
public final void showDirectDownloadAppDetailsWithExtra(String str, Bundle bundle, IAppHubDirectDownloadServiceCallback iAppHubDirectDownloadServiceCallback) {
C4281e c4281e = AbstractC1870m0.f5700a;
AbstractC1838d0.m3826C(AbstractC3671n.f11554a.f6073w, new C2823r(this, str, iAppHubDirectDownloadServiceCallback, bundle, null));
}
C2823r implements a Kotlin coroutine continuation with entry point mo410r(). After validating the ad token (details here), mo410r() passes execution to BinderC2829u.m4811d():
I examined a variety of user complaints relating to unwanted installations while viewing ads within other apps. When I spot-checked the apps giving rise to complaints, they all had a BIND_APPHUB_SERVICE line in its permission. I did not see complaints pertaining to apps that lacked this permission.
Games embed the AppLovin SDK which sends execution to AppHubService
Games (and other apps) embed the AppLovin SDK in order to show AppLovin ads. Within that SDK, the AppLovinAdServiceImpl trackAndLaunchClick() click handler decides what to do when a user taps an ad. If Direct Downloads are enabled, execution flows to startDirectInstallOrDownloadProcess().
public void trackAndLaunchClick(final AbstractC1760e abstractC1760e, final AppLovinAdView appLovinAdView, final C1562b c1562b, final Uri uri, MotionEvent motionEvent, boolean z, Bundle bundle) {
if (abstractC1760e == null) {
if (C1886x.m8960Fn()) {
this.logger.m8974i("AppLovinAdService", "Unable to track ad view click. No ad specified");
return;
}
return;
}
if (bundle != null && Boolean.parseBoolean(bundle.getString("skip_click_tracking"))) {
if (C1886x.m8960Fn()) {
this.logger.m8971f("AppLovinAdService", "Skipping tracking for click on an ad...");
}
} else {
if (C1886x.m8960Fn()) {
this.logger.m8971f("AppLovinAdService", "Tracking click on an ad...");
}
boolean z2 = bundle != null && Boolean.parseBoolean(bundle.getString("install_click"));
maybeSubmitPersistentPostbacks(abstractC1760e.m7560a(motionEvent, z, z2));
if (this.sdk.m8051BW() != null) {
this.sdk.m8051BW().m7426a(abstractC1760e.m7563d(motionEvent, false, z2), motionEvent);
}
}
if (appLovinAdView != null && uri != null) {
if (abstractC1760e.isDirectDownloadEnabled()) {
this.sdk.m8093Cr().startDirectInstallOrDownloadProcess(abstractC1760e, bundle, new ArrayService.DirectDownloadListener() {
@Override
public void onAppDetailsDisplayed() {
AppLovinAdServiceImpl.this.sdk.m8080Ce().pauseForClick();
C1562b c1562b2 = c1562b;
if (c1562b2 != null) {
c1562b2.m5913qX();
C1870m.m8646a(c1562b.m5907qQ(), abstractC1760e, appLovinAdView);
}
} ...
startDirectInstallOrDownloadProcess() sends execution to appHubService.showDirectDownloadAppDetailsWithExtra()
public void startDirectInstallOrDownloadProcess(ArrayDirectDownloadAd arrayDirectDownloadAd, Bundle bundle, DirectDownloadListener directDownloadListener) {
if (this.appHubService == null) {
if (C1886x.m8960Fn()) {
this.logger.m8974i(TAG, "Cannot begin Direct Install / Download process - service disconnected");
}
directDownloadListener.onFailure();
return;
}
if (!arrayDirectDownloadAd.isDirectDownloadEnabled()) {
if (C1886x.m8960Fn()) {
this.logger.m8974i(TAG, "Cannot begin Direct Install / Download process - missing token");
}
directDownloadListener.onFailure();
return;
}
try {
Bundle directDownloadParameters = arrayDirectDownloadAd.getDirectDownloadParameters();
if (bundle != null) {
directDownloadParameters.putAll(bundle);
}
this.currentDownloadState = new DirectDownloadState(arrayDirectDownloadAd.getDirectDownloadToken(), directDownloadParameters, directDownloadListener);
if (C1886x.m8960Fn()) {
this.logger.m8971f(TAG, "Starting Direct Download Activity");
}
if (this.appHubVersionCode >= 21) {
this.appHubService.showDirectDownloadAppDetailsWithExtra(this.currentDownloadState.adToken, this.currentDownloadState.parameters, this);
} else {
this.appHubService.showDirectDownloadAppDetails(this.currentDownloadState.adToken, this);
} ...
showDirectDownloadAppDetailsWithExtra() sends execution to AppHub using mRemote.transact():
It is extraordinarily rare for a company of AppLovin’s size to be caught placing software on users’ devices without their consent. The closest parallel is the 2005 revelation of Sony installing DRM software onto users’ computers without notice, without a EULA, and even when users pressed Cancel. That misconduct triggered enforcement by multiple state attorneys general, private lawsuits, seven-figure settlements, recall of affected CDs, and lasting reputational damage for Sony.
A similar trajectory is plausible for AppLovin. If others come to share my view that AppLovin installed apps without user permission, the company will be a pariah in online advertising. Trust in AppLovin’s auctions, privacy practices, and overall integrity would collapse. Some advertisers currently pay AppLovin both to sell them ad placements and to measure the effectiveness of those ads—which would suddenly seem ill-advised. Allegations in investors’ spring 2025 critiques—previously dismissed as speculation—would become more credible. If critics were right about AppLovin’s install practices, allegations about misbehavior in ad targeting, bid handling, and auction integrity are plausible too.
Google may also react strongly. AppLovin’s tactics circumvent Android security and Play Store protections—similar to other abuses Google previously punished (e.g. its 2018 removal of Cheetah Mobile apps). Google could respond by disabling or removing apps that connect to AppHub, by disabling or removing apps that were installed by AppHub, or by alerting users. Imagine a pop-up: “Your carrier preloaded your device with an install helper that lets third parties install apps without your consent. Google has detected 7 such apps on your device. Would you like to disable the helper and remove those apps?” The impact on AppLovin would be severe. In fact user complaints specifically ask Google to take action: “I believe this is illegal and am going to report it to Google as well.” (Rachel H), “This is nefarious and should be deplatformed by Google” (Colleen Ember), “Google needs to know about this” (Johnson David), “This should be banned from the Google Play store!” (Philip Mecham). With AppLovin intruding onto users’ devices—not “just” draining advertisers’ budgets—there is a strong case for Google to act.
Reading a draft of this article, some people asked about the revenue and profit implications. Rough calculations say the numbers are material:
Android holds >70% global market share, but high-value users skew toward iPhone. Suppose Android accounts for ~40% of value-weighted usage.
Of Android devices, AppLovin’s manufacturer and carrier deals may cover ~40%, giving ~16% of devices where installs could occur without consent.
AppLovin claims an audience >1 billion devices. If AppLovin placed just two unwanted apps on each device each year, that would be ~300 million installs per year.
At $1 per install (a fraction of AppLovin’s estimated average), that’s $300 million of revenue annually. With no payment to carriers, manufactures, or source apps, this revenue drops straight to the bottom line, yielding about 20% of AppLovin’s 2024 net profit.
The true impact could be larger. Legal fees, settlements, and regulatory penalties will weigh on earnings. Distrust among advertisers and partners could impede future business. Device manufacturers and carriers may have been prepared to look the other way, but are unlikely to let AppLovin continue once these problems come to the fore. And if Google disables AppHub or warns users, AppLovin risks losing not just future revenue but also its installed base.
I gathered 208 distinct complaints centered around the same problem: while a user played one game, another game was installed without consent. Representative examples:
“Instead of giving people the option to download the games when tapping on advertisements, the games automatically download to the device when the ads are tapped.” (PanPizz, October 31, 2023, emphasis added)
“I was watching ads on the webtoons app and it seems that rather than prompting a download through the play store. The advertisements for wordscape and tower war are basically auto downloading themselves to my phone. (Merlin2v, January 23, 2024, emphasis added)
“whenever I get an advertisement on IbisPaint, that app automatically downloads onto my phone” (BlackberriedGoat, September 4, 2023, emphasis added)
“you click anywhere and it automatically installs, doesn’t go through Google Play” (Punkminkis, January 5, 2024, emphasis added)
“I accidentally click on an ad when trying to click the x or skip button and the next thing I know I’m getting a notification that says tap to launch game.” (Disastrous-Jury4328, January 16, 2024, emphasis added)
“Multiple times after watching an ad in Hero wars: Alliance I’ve found a new game installed on my phone when I DID NOT touch anything to download and install.” (GreggAlan, March 16, 2024, emphasis added)
“Accidentally touch the screen during ad play and the game being advertised will be automatically installed without your consent.” (Lukas Landing, December 19, 2023, emphasis added)
“Optional ads also install other games WITHOUT PERMISSION. I’ve had to uninstall spam games over and over.” (Graham Curnew, August 9, 2024, emphasis added)
“Three times now I’ve gotten that ad for Tower War and any 30 seconds after the ad is over I get a push notification that Tower War has finished installing and is ready to play.” (JetJaguardYouthClub, August 24, 2023, emphasis added)
Some complaints specifically attribute unwanted installations to AppLovin or AppHub:
“It somehow installed apps from AppHub. How do I access AppHub to remove unwanted apps?” (Pomonian, May 25, 2025)
“Partnered with AppLovin, which if you misclick on their ads it automatically installs the game for you unless you notice and manually stop it” (Doom Clasher, July 3, 2024)
“Try deleting the app “apphub” … I noticed a notification saying it automatically downloaded apps” (Fadelsart, December 23, 2023)
Others users attribute the installs to install helpers such as Content Manager, Device Manager, or AppSelector that device manufacturers and carriers allow AppLovin to use for installs. (Details from code analysis.) It is logical that users attribute the installations to install helpers. For one, Android notifications routinely announce that an app has been installed, and give the name of the responsible install helper. Two, if a user checks Android Settings > Apps, the section “App details” will reference the name of the install helper. Three, the app that triggers the install helper is present neither in the notification nor in Settings > Apps > … > App details, making it less likely that users will reference AppHub except on those devices where AppHub itself has installation permissions and does not use a separate install helper.
Credibility of user complaints
The user complaints are credible based on both consistency and level of detail. A few users might be mistaken—for example, by tapping “install” and later forgetting. But the volume and similarity of complaints, from hundreds of independent users, reveals a broader pattern.
More than merely discuss unwanted installations, many of the complaints give details consistent with my code analysis. For example, users overwhelmingly report that installations occur when they receive ads (see the top bulleted list above), which exactly matches what my code analysis indicates.
Some complaints address alternative explanations such as a user accidentally approving an installation. Complaints deny that with specific details that make their denials credible:
“Happened to me with royal match. I clicked the x. Yet it downloaded the game. Yes I would know if I clicked install or not.” (Sunfish1988, February 13, 2024, emphasis added)
“I sorted thru my apps shortly before downloading Wordscapes last month, so I know I had no unwanted games on my phone at that time. Since then I’ve deleted 4 new games that I did not consent to download or even realize were downloaded.” (Jadiegirl, January 24, 2024, emphasis added)
“I noticed that whenever the game had a trial and I touched the screen it would slash to the screen that looked like Google Play and the Install Button would have the word “Cancel” on it as though I’d initiated the download (which I didn’t).” (Thotiana777, April 25, 2024, emphasis added)
“the ads for other games are very predatory and self install without permission if you miss the ‘x’ to close them by a milimeter” (Thin Richard, April 23, 2025, emphasis added)
Complaint with screenshot attributing installations to AppHub
A few complaints are include screenshots showing the problem. For example, Reddit user Guilty_Astronaut5344 preserved a post-install notification attributing three unwanted installs to AppHub.
Complaints reporting countdown timer, and showing the countdown in video and screenshot
Other complaints are particularly credible because they match even more specific details from the AppLovin code. For example, three users reported countdowns leading to automatic install:
“Just today I’ve seen them implement a 5-second “countdown” to the program installing the game, but stopping the countdown STILL INSTALLS THE GAME WITHOUT YOUR CONSENT.” (PanPizz, October 31, 2023)
“I’ve come across some really shitty ad tactics that will auto install the app they’re pushing if you click anywhere on the screen before the timeout. Even if you just back out, if you don’t actually hit cancel install then you’ll get some stupid questionable games installed …” (dontthink19, January 7, 2024)
“Mobile game ads can now just install themselves without you tapping Install, wish is now replaced by ‘Install now’ if you want the game 5 seconds sooner. Hitting the X instead of Cancel still installs the game” (nascarsteve, December 10, 2023)
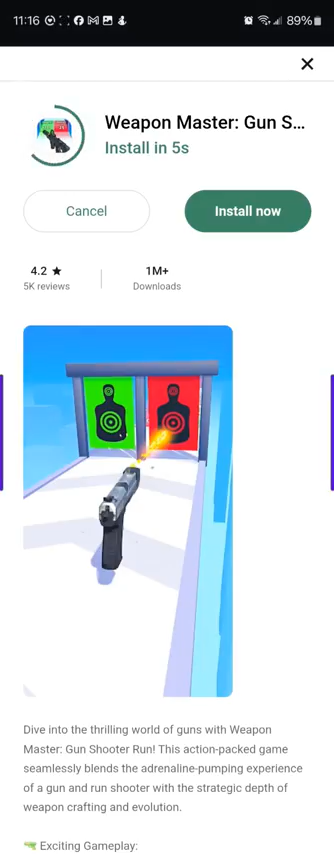
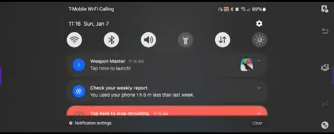
Not only does the general concept of a countdown-to-install match what I found in AppLovin code, the first and third comments also mention the duration of the countdown, from 5 seconds. This matches the “AutoInstallDelay” default countdown duration listed in AppLovin code. (The code sets a duration of 5e3, meaning 5×103=5000 milliseconds, matching the complaints.) Remarkably, user dontthink19 faced the countdown-to-install ads often enough, and predictably enough, that he was able to capture one such installation on video – showing an ad, then the countdown to install, then the app installed, then him uninstalling it, all in a single continuous video file. Key screenshots from dontthink19’s video:
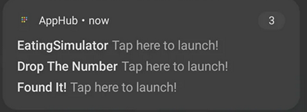
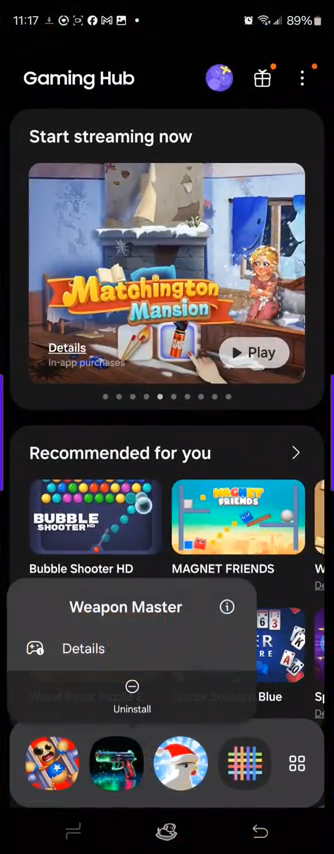
0:03 Start of advertisement promoting Weapon Master0:19 Conclusion of advertisement promoting Weapon Master0:20 “X Install Screen” for Weapon Master, which opened automatically, and says it will “Install in 5s”0:31 Confirmation of Weapon Master installed. Small text at center reads “Weapon Master” “Tap now here to launch!”0:39 Weapon Master is indeed installed, albeit available for uninstall
The countdown videos and screenshots also match yet other details from AppLovin code. In the countdown-to-install screen, notice the unusual label “Install in 5s” (using the abbreviation “s” for seconds, with no space between the number and the letter s). This exactly matches the pattern in AppLovin code I found—further confirming that AppLovin is responsible for this installation.
Complaints about installation upon clicking x
Numerous users report that clicking an x, or trying to click an x, nonetheless causes an app to install. Combining source code and user complaints, two types of complaints are at risk of being combined:
Users who received what I call the X Install Screen (step 3 in the Weapon Master sequence above), and who tapped the X in that screen (which is an installation pathway in the IsOneClickInstallOnCloseEnabled JavaScript logic).
“Mobile game ads can now just install themselves without you tapping Install, wish is now replaced by ‘Install now’ if you want the game 5 seconds sooner. Hitting the X instead of Cancel still installs the game” (nascarstevebob – December 10, 2023, emphasis added)
“Even if you just back out, if you don’t actually hit cancel install then you’ll get some stupid questionable games installed …” (dontthink19, January 7, 2024, emphasis added)
“It definitely auto-installs. I’ve tested it because I was wondering where tf all these random shitty game apps were coming from in my phone. I don’t click anything, and if you don’t select “cancel” when it starts installing, the game will install. If you try to exit out, it does not count and will still install the game.” ([deleted] – January 22, 2024, emphasis added)
Many others, such as the following, could be either type 1 or type 2 above—but either way, indicate users’ dissatisfaction at installations occurring when users try to exit and decline.
“There are now ads that autoinstall other apps on your phone! They look like interactive/minigame ads, but touching ANYTHING – the close button, trying to pull up the phone navigation bar to exit WS – will trigger these apps to start installing.” (Star Donovan – February 2, 2024 on Google Play, emphasis added)
“the straw that broke the camel’s back was how exiting the ads forces you to download them. I’ve deleted 5 apps I did mot want to download.” (Casey Kristin Frye – December 23, 2023 on Google Play, emphasis added)
“They run adds on other games, you click to close out the automatic install, surprise you’ve downloaded the game for the 59th time!” (Luke Williams – September 17, 2024 on Google Play, emphasis added)
“Game installed itself by me trying to exit an add on another game” (Ian Kelley – June 23, 2024 on Google Play, emphasis added)
“It installed itself into my phone when I tried to exit an app that was showing an ad for this. This is super shady on their part and should be looked into” (Parker Abegg – December 14, 2023 on Google Play, emphasis added)
Scores of similar complaints
The following list presents 208 relevant complaints from Play Store, Reddit, and other online discussions. Some complaints are excerpted to the relevant section, but spelling and punctuation are unchanged.
I had this problem too and managed to Google some suggestions that seem to have prevented this from happening again. I don’t recall the instructions exactly but the short version is that my phone manufacturer (in my case, Motorola) had some pre-installed app(s) that allow auto installation from ads. I couldn’t uninstall the apps but I disabled all the suspicious ones/likely suspects based on my Google-fu, and that seems to have done the trick.
I was playing a game when an ad popped up and it showed one of those scam “free” money ads and it somehow installed itself without me pressing anything. I didnt accidentally click on the ad or anything, it just automatically installed when the ad started playing.
I’ve had that happen and I’m sure I didn’t install it by mistake. I checked the app that installed the adware and it was my Telco provider app that installed the ads, and they installed all at the same time, it’s annoying as shit.
I was having the similar problem with ads showing Klondike Farm Adventures. Without even touching the screen it would automatically download and it was downloading not through Google Play Store but through Samsung game store.
This game (or its ads) can illegally download and install games onto your device without your consent or knowledge. These games (all from different developers) suddenly appear on my phone on the very last screen. They’re nothing I’d ever play. I’ve never even heard of “Tiledom” or “2248 Numbers Merge,” by Funvent Studios or Play Simple Games. This is the 3rd time this game has done this. I don’t know how, but I’m sure it’s this game.
Recent update just pumped it onto my phone and without me allowing it, it’s going through and installing dozens of pos mobile games. It’s invisible to the user and cannot be disabled or uninstalled.
Ads pop up and install games without being prompted. Pop up ads are frustrating. They open without being clicked and navigate away from the game. Sometimes installing new games without being prompted…very frustrating
My phone just started installing random apps to my secure folder. It is called ‘AppHub’ but I can not see the any app called ‘AppHub’ both main stetting -> App and secure folder setting app. Do anyone facing the same problem? I m sure these app were malicious and asked the root permission :/
My phone just started installing random apps to my secure folder. It is called ‘AppHub’ but I can not see the any app called ‘AppHub’ both main setting -> App and secure folder setting app.
It installs other apps from the ads it shows you. AUTOMATICALLY WITHOUT MY PERMISSION!
Note: Game developer did not deny forced installations: “Hey! We’re not huge fans of ads either, but we can’t keep our game free without them. They help us develop new features, maintain the app, and release updates. We’d love it if you changed your mind. Come back soon!”
Wrong. It definitely auto-installs. The little “X” pops up, but when you click it – you just clicked on the ad (NOT an “install” button) and it installs. I’ve just now had to uninstall two crappy games from my phone, Merge Mansion and some other crap. This is infuriating and should not be legal as it is bypassing my security settings and installing things without my permission.
Your ads are auto installing apps in the background… You stopped it for a while now it started again. This needs to stop!!! update, ads are getting worse.. false X seem to be the standard..
BEWARE OF OTHER APPS BEING INSTALLED WITHOUT YOUR PERMISSION… written by people who use full screen ads to install various other apps [MOB CONTROL game app] ****** when you try to click the [x] button to close the pop up ad it vanishes (w/ split second timing) and is replaced by an OK button
i keep getting ads for this game with a fake x. When i click the x, it automatically installs this game without my permission. I’ve had to uninstal it 5 times now
Caution: this game’s ads will automatically download games without your permission. It did this to me with 4 apps that played as ads. I had to manually go in and uninstall.
somehow the games in the ads install themselves. When I try to click on “x” to close the add, it connects to a website or play store and even before I can close them, voila, those games are installed on your phone. Be very careful!!
Partnered with AppLovin, which if you misclick on their ads it automatically installs the game for you unless you notice and manually stop it, inflating their download count. I did not knowingly download this “game.” I did not click “install.” How is this even legal?
Careful with this game. If you even try to stop an ad between gameplay, it will automatically install other games on your phone without asking. I had about a dozen games in my phone without even realizing it. I uninstalled those as well as this game. Never again.
I get this a lot. If I don’t click anything, the app installs itself on my phone. If I click the ‘x’, the app auto installs on my phone. The only way I can make it stop is to press the cancel button.
this application have so much control on device that it automatically installs other games on device without permission. This is sheer violation of privacy and recommended not to be installed.
Help! Device Manager is auto-iinstalling apps from ads. Some games from google play have ads that auto download applications. I traced it back toT-Mobile’s Device Manager allowing malicious ads to auto install applications. That’s right, just watching the ad downloads an app. T-mobile has made it impossible to disable this app. I am fearful of this massive security hole. I am scared of malicious apps being downloaded. I have seen other complaints over the last few months. What can I do fix this major security hole? … All I know is that the malware ads come from something called applovin. … It is just too much of a security risk that that T-Mobile has created with their Device Manager allowing allowing 3rd parties to automatically download and install of potential malware.
Then I noticed that whenever the game had a trial and I touched the screen it would slash to the screen that looked like Google Play and the Install Button would have the word “Cancel” on it as though I’d initiated the download (which I didn’t). When I tried to hit cancel it would go back to the trial play thing and back and forth until I just X’ed out of it.
They utilize ads in other games to AUTOMATICALLY INSTALL this trash on your phone. Absolute slimiest tactic to get me to play your garbage game I’ve ever seen.
If you accidentally touch an ad, it automatically installs an app on your phone.
Note: Game developer did not deny forced installations: “Thank you for reporting this problem with our tower war tactical game. We will try to fix it as soon as possible so that you can continue to enjoy it.”
I can’t leave reviews of the apps that are auto download in fact when I look at app info they say the apps are downloaded by device manager and not google play.
I found an app called Content Manager on my Samsung S24 that I bought through T-Mobile. There was an option there that says “Allow Install of New Apps” and I turned it off, and the ad installs stopped. I think it’s seriously f-ed up that things like this are allowed.
I accidentally downloaded this just by clicking on an AD. JUST BY CLICKING ON IT. Not to be confused with accidentally pressing the download button on the AD. These advertisements are getting scummier and shadier by the day. What’s next? Are you going to turn wordscapes into a self reinstalling virus? We live in the lamest dystopia possible.
I watched an ad for Wordscapes for a different game I play and they INSTALLED this app WITHOUT my PERMISSION!! I didn’t click on anything and even if I accidentally did (I didn’t), Wordscapes doesn’t have the right to download their app onto my phone without my permission!!! I believe this is illegal and am going to report it to Google as well. **I deleted it when I saw it was downloaded onto my phone, but had to reinstall it to make this review**
Multiple times after watching an ad in Hero wars: Alliance I’ve found a new game installed on my phone when I DID NOT touch anything to download and install.
It’s been happening to me constantly and I’m so tired of it. Can’t figure out how to kill that function or at least make the damn thing wait for a prompt so I can say no. I’m on a Samsung Android with all of my security settings as recommended (apps only from Play or Samsung Store, ask permission before downloading or updating apps on any network, etc.). I’ve filed a few customer support requests with Snowprint, who have always been helpful and offer apologies but don’t seem to have solved the issue. Block Blast, Merge Mansion, Overmortal, Wordscapes… The list goes on.
It’s not coool, nor should it be legal for your ads to automatically install games on my phone.
Note: Game developer did not deny forced installations: “Thank you for reporting this problem with our tower war tactical game. We will try to fix it as soon as possible so that you can continue to enjoy it.”
I freaking hate this BS. I have searched every setting possible and can not figure out how to turn it off or prevent it. I have noticed that it only does it through Galaxy Store. Not Play. If anyone has figured out how to stop it, lmk.
An ad played for this game and without any input on my end, INSTALLED ITSELF ON MY PHONE. This is ridiculous how dare you install your product on my phone without my permission. The ad played. I did not touch it didn’t even touch my phone screen and still it’s on my phone. This is neither legal nor ethical and it is extremely concerning as to what this game is. If this happens again I will be seeking legal action against your company. Absolutely ridiculous.
I get this app as an ad, and when I try to close the ad and I fail, it doesn’t just take me to the play store to download it, it actually force installs on my phone without me giving permission to download app or install. I don’t like the fact this app is force installing on my phone from ads and not from the play store. I would give this game a try if it didn’t force me to install it and actually gave me a choice instead. Absolutely unacceptable, acting like a virus rather than an app.
One of many games that have taken the ad program where it will install itself on your device when you close the ad. If it weren’t for that it would be a good game. But just auto installing itself on your device is something that defines what a Virus is.
This ap has installed itself without my permission after seeing an ad in another game. This is nefarious and should be deplatformed by Google for this behavior.
Installed without my consent. It was installed during an ad from another app with no way to cancel or even see it installing. I didn’t even notice until my phone said, “Moving to game hub.” If their ads install the app without consent, what else will this completely untrustworthy company will install while app is installed? No thank you.
YES. I sorted thru my apps shortly before downloading Wordscapes last month, so I know I had no unwanted games on my phone at that time. Since then I’ve deleted 4 new games that I did not consent to download or even realize were downloaded. Very sketchy. I’ll be watching my apps closely from now on. I obviously like Wordscapes, but if this continues to happen, I’ll probably delete it.
Disappointed has started those auto install adds where it starts installing and you have to cancel and ended up with 2 unwanted games so just Uninstalled this app after playing for a long time.
Hello, so I was watching ads on the webtoons app and it seems that rather than prompting a download through the play store. The advertisements for wordscape and tower war are basically auto downloading themselves to my phone. When I checked to see what store installed it, it says it was installed by Device manager.
Does anyone else seem to have apps downloaded to their device after playing Wordscapes? I seem to have some of the apps on my phone now that appear in the ads, but did not download them.
It happens to me on the mobile games I play. I accidentally click on an ad when trying to click the x or skip button and the next thing I know I’m getting a notification that says tap to launch game. I get it so many times with fishdom and I just got it with tile match.
WARNING THIS APP IS MALWARE IT AUTO-INSTALLED ON MY DEVICE THEY USE A SPECIFIC AD THAT AUTO-INSTALLS ON YOUR DEVICE IT IS NOT AN ACCIDENT AVOID THIS APP
I’ve come across some really shitty ad tactics that will auto install the app they’re pushing if you click anywhere on the screen before the timeout. Even if you just back out, if you don’t actually hit cancel install then you’ll get some stupid questionable games installed … It’s happened to me 3 times now. I’m looking for new games to play and when ads are served in that manner, I’ve had to go back and uninstall them. They don’t magically install themselves. You misclick on the ad and it opens up to a timer you have to cancel or it’ll get installed
Note: With video at https://imgur.com/a/YzXCWzV showing 5-second countdown followed by auto-install. Countdown narrative and 5 second threshold match AutoInstallDelay in code.
Game is decent. However, last night one of the adds turned out to be self installing malware. It took me 20 mins to remove the malware and everything it installed.
I’ve seen the ads OP is talking about. It’s got a quick download or something, you click anywhere and it automatically installs, doesn’t go through Google Play.
One of your ads was installing this game without my permission, and when it was done, it booted up in front of my phone game. Stop doing this. This is outrightfully idiotic.
Ads that download an app on to my device if I click anywhere are offensive and dangerous. Having 30+ second, phased, unskippable ads, that download apps on to my device is downright insulting.
Wordscapes currently has an AD going around on other apps that will FORCE INSTALL THE GAME DURING THE AD AND IT CANNOT BE CANCELLED. These predatory ADs were found in a game called Water Sort. Wordscapes forced installed their app on my device without permission multiple times and they should be FINED.
I was playing another game and this ad showed up i tried to click the x it took me to the download and started it automatically I then hit cancel thinking nothing of it then later check my phone and it was installed against my consent
I’ve had this happen to me with the tower war playable ad about a dozen times. They updated their ad a couple weeks ago and it stopped, but a couple days ago they changed the ad back and it is happening again.
Installed itself. While playing a different game, I got an ad for this game and thought I closed it. A couple minutes later I got a notification that it was done installing.
I got an ad for it and then a long lasting black screen with an install button. The x mark is so small that you are likely to miss it. Turns out the WHOLE SCREEN is an install button and it automatically installs, even if you hit cancel. Very shady.
Try deleting the app “apphub” (i had to search it in the settings of the phone to actually find the app) I noticed a notification saying it automatically downloaded apps (this was a notification from the phone itself on the day of purchase) and saw this “apphub” app that says it “provides a friction free download service for in-game ad choices” and it immediately set off a red flag for this issue we’ve been having. So far it seems to have worked but I will update if it happens again. The worst part about it is that I have parental controls set up on my child’s phone and it was bypassing them to auto-download these ads despite my approval being necessary to download anything.
DONT HAVE YOUR GARBAGE “GAME” 1-TAP INSTALL WHEN ALL I’M TRYING TO DO IS X PAST YOUR AD. I DONT WANT YOUR GARBAGE, STOP INSTALLING YOUR TRASH ON MY PHONE.
This thing keeps getting installed on my phone without my knowledge. I have to uninstall it regularly. It’s got ads on my other apps and somehow gets installed by itself! Google needs to know about this.
He’s right, I’ve had three games auto install. It happens on the ads that play extra long credits. Typically, you won’t be awarded for the completion of the add and another add will play. This literally happened to me today for the third time.
Yeah this is a thing I’ve been having happen recently. The apps install themselves. Even if you don’t click the X to end the ad, the still install themselves. … they fully go and install themselves at the end of the video. It’ll show the download bar at the top and the app will be with all the other apps.
Mobile game ads can now just install themselves without you tapping Install, wish is now replaced by ‘Install now’ if you want the game 5 seconds sooner. Hitting the X instead of Cancel still installs the game
I’ve had idk how many game ads lately send me to the app store when I tried closing them. In fact, I KNOW I didn’t download anything, and recently found 2 apps on my phone that had gotten downloaded. Had to have happened in the past couple days. Never opened them, promptly deleted them. Just annoyances. Especially when they’re things I’d NEVER use like insta or tiktok.
Instead of giving people the option to download the games when tapping on advertisements, the games automatically download to the device when the ads are tapped. No consent is given to the users when it comes to when they want to download the games or not, as soon as you tap on the ad it downloads for you. … AppLovin are now essentially baiting you with a demo and then forcing the full game down your throats. Just today I’ve seen them implement a 5-second “countdown” to the program installing the game, but stopping the countdown STILL INSTALLS THE GAME WITHOUT YOUR CONSENT. …
Security threat! Automatically installs from ads without permission or consent, then starts sending push notifications. uninxstalled immediately without launching. No means no!
Game was good and fun for a while until I noticed that if you clicked the ad accidentally, you run the risk of having some of the apps automatically installed. Ended up with 2 games that I did not want on my phone. BS practice.
Why does the game download apps whenever I watch an ad?” “This only started to happen recently. I would have my phone on the side and watch the dragon TV ads and whenever I was done, there would be an app installed.
this stupid game keeps getting automatically installed by ads in other games. I do not want to play this game and your disgusting tactics of forcing a download that I DO NOT WANT ON MY PHONE border on criminal.
An ad for this app keeps popping up on my phone. When I try to close it, the app installs. Please do something about this glitch. No that doesn’t help. If I don’t want an app and I’m trying to close an ad, I would expect that it not automatically download on my phone regardless.
This app keeps installing itself every time I watch an ad for it. Even if I do not touch my screen at all throughout the whole ad, it still installs itself after playing. I’ve deleted this app both too many and not enough times. I will continue deleting it.
I will never use this app. The developers push deceptive ads in other applications that automatically install Wordscapes on your phone when you try to close the ad. This is deceptive behavior and I’ve reported this to the Play store.
Ad automatically installed an app? … So it’s as the title says. I played an ad in the game, and it automatically installed an app (It was bricks and balls) I never left the AR app and I only realized it happened because I got a notification that said “click to launch the bricks and balls app. … So I went and checked and…yep it had been installed.
Ad for this game appeared and while trying to x out of it, accidentally clicked the ad. A minute later i receive a notification that Wordscapes installed. Never clicked on an install button. Shady practices.
This game literally installed itself while I was trying to make an ad go away in Brotato. No redirect to the play store. No confirmation on the install. you miss the x on the corner and now you have a new game installed that you never asked for. absolute scumbag design. 0 out of 10.
Game itself is fun, you ruin it with ads for apps that auto install on your device. I can deal with ads you can close but not ones that install themselves and you have to close your game to go uninstall the unwanted app.
The problem that I am seeing now is that when you encounter an ad, it automatically installs the game listed in the ad. This is happening every time I play the game. I am ready to delete the game at this point. The frustration of having to uninxstall the latest game you force download is too much.
Disabled on both our phones the day we got home with them. But woke up a few days ago with screen like OP posted (both phones). Somehow the app selector got turned back on without our knowledge.
You can disable AppSelector and you’ll never see those again (at least I’ve been through a few updates now and I haven’t seen it). I always recommend people uninstall or disable AppHub and AppSelector. One of those apps will also just straight up install apps on your behalf without your knowledge, so if you don’t get rid of those two apps and you see random apps mysteriously appear, that’s why. They’re T-Mobile malware that gets preinstalled on carrier versions of android devices that T-Mobile sells. AT&T and Verizon do the same thing unfortunately.
Hello, for the past two or three days, whenever I get an advertisement on IbisPaint, that app automatically downloads onto my phone. Does anyone have this issue / know how to fix this?
Three times now I’ve gotten that ad for Tower War and any 30 seconds after the ad is over I get a push notification that Tower War has finished installing and is ready to play. Sure enough, there’s the game, loaded onto my phone without my permission. The only thing I clicked on was the “x” to close the ad once it was done. Kinda creeps me out that an ad can bypass the store and just install unwanted crap on your phone
several Game ads will auto-install the games, no input or knowledge of it happening from you, you simply have several new “games” in you menu. Spyware/virus/predatory behavior.
Nope, T-Mobile does for a fact install it automatically as does every other carrier with their own version. I set up my own S23 Ultra. I’m always very careful with every prompt that pops up, I read it carefully, uncheck anything opting me into spying or other malware features, etc. Yet after setup I was finding random apps being installed on my device and the App Hub, AppSelector, and AppManager were all culprits that I did NOT opt in to.
HATE THE AUTO INSTALL ADS! YOU DO NOT HAVE PERMISSION TO INSTALL APPS ON MY PHONE! AS I TRY TO CLOSE THE ADS, IT WILL AUTO INSTALL APPS TO MY PHONE. GET RID OF THOSE ADS!
Every time an ad plays for this game, while I’m playing a game that I enjoy, it is automatically installed on my device. If this continues, I am willing to start a class action lawsuit. It isn’t legal to use these practices, and I consider it harassment
This ad if accidentally clicked doesn’t even take you to the store to ask if you wanted to download. It just installs. That’s crazy invasive to your device, like a bug. Or a parasite. Once again, marketing work being done by ignorant sales kids who don’t understand law.
Fun game but ads are extremely intrusive. If you try to exit the ad, other games are autoinstalled which can open your device to viruses or other bad actors.
They use other apps to install RM without permission to boost their numbers. I now uninstalled this app at least 7 times – all ads from other apps that unethically installed without permission.
There are now ads that autoinstall other apps on your phone! They look like interactive/minigame ads, but touching ANYTHING – the close button, trying to pull up the phone navigation bar to exit WS – will trigger these apps to start installing. Sometimes you can cancel w/i 1 second, other times there is no cancel so you have to remove these malicious installations later.
I did not choose to install this on my device. The mobile ad for this would not allow me to exit and then this installed without my permission. I understand advertising is important but do not trust an app this invasive.
It definitely auto-installs. I’ve tested it because I was wondering where tf all these random shitty game apps were coming from in my phone. I don’t click anything, and if you don’t select “cancel” when it starts installing, the game will install. If you try to exit out, it does not count and will still install the game.
Ads, I understand. I draw the line at forced installations. I had this app for so long and it was one of the more peaceful ones. They sadly introduced ads, which is annoying but understandable. Now the ads have gotten so intrusive I get more ads than game time. However the straw that broke the camel’s back was how exiting the ads forces you to download them. I’ve deleted 5 apps I did mot want to download.
Note: Game developer did not deny forced installations: “Our team hears you and we’re working to improve the ad experience for you. For now, you may consider getting the premium version to enjoy an ad-free version of the game.”
It installed itself into my phone when I tried to exit an app that was showing an ad for this. This is super shady on their part and should be looked into
Had an advertisment of wordscapes and after it finished it installed itself when I was trying to exit the advertisment. Very sketchy that it installed itself this way
Everytime one of their Royal Match advertisements come up while I’m playing a different game, it force-installs Royal Match game app on my Samsung phone without my consent! I don’t know how to block it from installing! Negative 5 stars! This should be banned from the Google Play store!
Royal Match keeps downloading itself to my phone – without my permission. I play Uno and they have ads for it. And for the past week, it has been automatically downloading itself to my phone.
Keeps installing on my phone every time I see an ad for it. I’ve never wanted this game and I’ve never played it. Just sick as hell of deleting it from my phone.
DO NOT INSTALL- Lately it has become difficult to exit out of the ads, which I had no problems with before. The issue now is that when I exit the ads, it begins to install the app for those ads immediately instead of simply bringing up the playstore where I have the OPTION to install. Frankly these ads that automatically download different apps make me feel that this game is UNSAFE to continue playing. What a dissapointment. This isn’t a fluke either as many friends of mine faced the same issue.
Somehow ended up on my phone,so I thought I’d leave a little insight as to how predatory the way-too-long ads are for this game. I believe it installed itself after a misclick on the ‘X’ to close the ad. A bit scary.
Culper 1 also presents correlation between AppLovin deals with OEMs and carriers in certain regions, spikes in installs in these regions, and spikes in user complaints. The most natural explanation is that the OEM and carrier relationships made it possible for AppLovin to install numerous apps onto users’ phones in affected regions – causing both a spike in installations, and a spike in user complaints. Notably the OEM and carrier deals pertained to Android only, not iPhone, and the installation spike similarly appeared for Android only.
Ordinarily, if app A wants to install app B, it must send the user to Google Play—where installation only proceeds if the user taps the prominent green Install button. At Google Play, accidental installs are rare, and nonconsensual installs are effectively unheard of.
If installations occur outside Google Play, the first question is technical feasibility. It is not enough that source code appears to support this behavior (as shown in my execution path analysis); the Android security model must also allow it. A close review of security settings in the relevant manifests shows that such installs are indeed possible—and in fact, the unusual settings documented on this page are difficult to explain any other way.
Save The Girl manifest indicates authorization to invoke AppHub
The Android game “Save The Girl” includes the following entry in its manifest:
Ordinarily, apps do not need this line to receive ads from AppLovin. So why does this game—and dozens of others—request permission to invoke AppHub? What legitimate purpose does this serve?
AppHub manifest indicates authorization to invoke T-Mobile packages with elevated permissions
The AppHub manifest includes permission to interact with a T-mobile installer helper:
One plausible explanation is that AppHub uses a T-Mobile install helper to complete out-of-box (OOBE) installations. But that only raises a further question: Why would third-party games need to connect to the same privileged middleware?
Com.tmobile.dm.cm has elevated permissions including installing other apps
The com.tmobile.dm.cm package has the critical permission necessary to install other apps.
Some AppLovin APKs seek permission to install apps themselves, without a manufacturer/carrier install helper
In some cases, AppHub does not rely on a manufacturer or carrier install helper. Certain AppLovin APKs instead request install permissions directly. For example, the Adapt v3.40.2 manifest includes:
AppLovin’s public statements are consistent with AppLovin sometimes receiving this permission. From AppLovin’s Array Terms:
To provide the Array Services to you, we may need access to the “INSTALL_PACKAGES” and “QUERY_ALL_PACKAGES” Android device permissions. We receive these permissions through your carrier or mobile phone original equipment manufacturer, and we use them to provide you with the Array Services, including presenting Direct Download screen to you and facilitating the on-device installation of mobile applications at your election (where Array acts as the technical installer, not your carrier).
This paragraph — including phone manufacturer or carrier preinstalling AppLovin code and presetting these permissions — matches what I observed. Of course the “at your election” claim is contrary to my analysis of the execution path, and my tabulation of user complaints, indicating nonconsensual installations.
Flipping through AppLovin APKs, it is easy to find labels and strings that appear to indicate nonconsensual installations. Examples are below.
These labels must be interpreted with care. Ultimately these are labels, not directly indicating actual application functionality. Anyone could name a function FlyToMoon(), but that doesn’t mean he has a rocket or a launchpad.
Furthermore, there could be proper reasons for certain silent installs. Consider the out-of-box experience, when it is routine for manufacturers and carriers to place apps on a user’s device. Consider installations in which user consent is obtained in some earlier part of the process.
Overall, I consider the execution path a more reliable method of determining what AppLovin’s code does. On the other hand, the execution path is complicated—requiring parsing thousands of lines of code to follow the flow, and requiring substantial technical skills to understand the code. In contrast, reviewing strings can be as easy as Edit-Find and dictionary meaning.
Labels and strings in Java code
AppLovin’s code includes various labels that indicate or reference nonconsensual installations. A representative example: com.applovin.array.apphub.tmobile includes a class called TmobileSilentInstallManager. The literal meaning of a “silent install” is one without user consent.
Elsewhere in AppLovin code, there are hundreds of references to “Install”, “Installer”, “installing”, “startInstall”, and the like, including more precise labels such as “andr_app_installing_start”, “an.ui.ntfn.installing_progress.enabled”, and “package_installing_successfully_finished_notification_id”. AppLovin logging also includes status messages like “Failed to start install”, “Failed to start installing”. These labels and strings leave no doubt that AppLovin can install apps—but they do not prove that installations are silent, automatic, or nonconsensual. Other labels, like “DirectInstallOrDownload”, indicate a nonstandard installation (not via Google Play) and suggest the install has few steps (calling into question what disclosure is provided and what consent obtained), but again are less than complete proof.
Labels in JavaScript code
The AppHub APK embeds a resource file, index-BFfWBgBF.js, which contains labels indicating non-consensual “auto” installations. The file merits close examination (see my execution path analysis), but even its labels reveal its purpose. For example:
A JavaScript “Breadcrumb” message logger even records a possible event, “Installation on ‘X’ button click”. Yet clicking an X is ordinarily understood as rejection, not consent. Similarly, an error handler describes “Failed to set installation on dismiss enabled”—implying that, when working correctly, the code can indeed install on dismiss. But what user thinks “dismiss[ing]” an ad is basis for an installation? Code snippets below.
catch(a => {
pe.reportError(new Error("Failed to set installation on dismiss enabled", {
pe.leaveBreadcrumb({
message: 'Installation on "X" button click', ...
Taken together, these labels describe scenarios where installations proceed without a user being asked to install or without the user agreeing to install.
Possible settings screen entries consistent with automatic installations
The resource file index-BFfWBgBF.js also includes a potential settings screen with the following labels:
zu = "Enable Direct Download",
Gu = "Download apps with a single click", ...
Ra = { EnableDirectDownload: zu,
EnableDirectDownload_Description: Gu, ...
From the resource file alone, it is unclear whether this screen is ever presented to users, and if so, under what conditions or with what default setting. Yet users consistently report unexpected app installations, suggesting that the option may be enabled by default—or hidden in a screen users do not ordinarily open.
My personal experience reinforces doubt about such a screen being shown to users. In spring 2025, I purchased a new T-Mobile phone directly from the carrier. On first boot, the out-of-box setup prominently displayed AppLovin screens urging me to download apps. At no point did I see any option to “Enable Direct Download” or to “Download apps with a single click.”
User complaints confirm that no such screen is shown. In reviewing complaints, I found no screenshots of such a screen being proactively shown. One user noted:
I found an app called Content Manager on my Samsung S24 that I bought through T-Mobile. There was an option there that says “Allow Install of New Apps” and I turned it off, and the ad installs stopped. (Skybreak, April 6, 2024)
This complaint reinforces the problem: a user would have no reason to hunt through a Content Manager settings screen to disable unwanted installs. Nor does failing to disable a buried option constitute consent for arbitrary app installations.