Affiliate network requirements require shopping plugins to “stand-down”—not present their affiliate links, not even highlight their buttons—when another publisher has already referred a user to a given merchant. Inexplicably, Microsoft Shopping often does no such thing.
The basic bargain of affiliate marketing is that a publisher presents a link to a user, who (the publisher hopes) clicks, browses, and buys. But if a publisher can put reminder software on a user’s computer or otherwise present messages within a user’s browser, it gets an extraordinary opportunity for its link to be clicked last, even if another publisher actually referred the user. To preserve balance and give regular publishers a fair shot, affiliate networks imposed a stand-down rule: If another publisher already referred the user, a publisher with software must not show its notification. This isn’t just an industry norm; it is embodied in contracts between publishers, networks, and merchants. (Terms and links below.)
In 2021, Microsoft added shopping features to its Edge web browser. If a user browses an ecommerce site participating in Microsoft Cashback, Edge Shopping open a notification, encouraging a user to click. Under affiliate network stand-down rules, this notification must not be shown if another publisher already referred that user to that merchant. Inexplicably, in dozens of tests over two months, I found the stand-down logic just isn’t working. Edge Shopping systematically ignores stand-down. It pops open. Time. After. Time.
This is a blatant violation of affiliate network rules. From a $3 trillion company, with ample developers, product managers, and lawyers to get it right. As to a product users didn’t even ask for. (Edge Shopping is preinstalled in Edge which is of course preinstalled in Windows.) Edge Shopping used to stand down when required, and that’s what I saw in testing several years ago. But later, something went terribly wrong. At best, a dev changed a setting and no one noticed. Even then, where are the testers? As a sometimes-fanboy (my first long-distance call was reporting a bug to Microsoft tech support!) and from 2018 to 2024 an employee (details below), I want better. The publishers whose commissions were taken—their earnings hang in the balance, and not only do they want better, they are suing to try to get it. (Again, more below.)
Contract provisions require stand-down
Above, I mentioned that stand-down rules are embodied in contract. I wrote up some of these contract terms in January (there, remarking on Honey violations from a much-watched video by MegaLag). Restating with a focus on what’s most relevant here (with emphasis added):
Commission Junction Publisher Service Agreement: “Software-based activity must honor the CJ Affiliate Software Publishers Policy requirements… including … (iv) requirements prohibiting usurpation of a Transaction that might otherwise result in a Payout to another Publisher… and (v) non-interference with competing advertiser/ publisher referrals.”
Rakuten Advertising Policies: “Software Publishers must recognize and Stand-down on publisher-driven traffic… ‘Stand-down’ means the software may not activate and redirect the end user to the advertiser site with their Supplier Affiliate link for the duration of the browser session. … The [software] must stand-down and not display any forms of sliders or pop-ups to prompt activation if another publisher has already referred an end user.” Stand down must be complete: In a stand-down situation, the publisher’s software “may not operate.”
Impact “Stand-Down Policy Explained”: Prohibits publishers “using browser extensions, toolbars, or in-cart solutions … from interfering with the shopping experience if another click has already been recorded from another partner.” These rules appear within an advertiser’s “Contracts” “General Terms”, affirming that they are contractual in nature. Impact’s Master Program Agreement is also on point, prohibiting any effort to “interfere with referrals of End Users by another Partner.”
Awin Publisher Code of Conduct: “Publishers only utilise browser extensions, adware and toolbars that meet applicable standards and must follow “stand-down” rules. … must recognise instances of activities by other Awin Publishers and “stand-down” if the user was referred to the Advertiser site by another Awin Publisher. By standing-down, the Publisher agrees that the browser extension, adware or toolbar will not display any form of overlays or pop-ups or attempt to overwrite the original affiliate tracking while on the Advertiser website.”
Edge does not stand-down
In test after test, I found that Edge Shopping does not stand-down.
In a representative video, from testing on November 28, 2025, I requested the VPN and security site surfshark.com via a standard CJ affiliate link.

CJ redirected me to Surfshark with a URL referencing cjdata, cjevent, aff_click_id, utm_source=cj, and sf+cs=cj. Each of those parameters indicated that this was, yes, an affiliate redirect from CJ to Surfshark .

Then Microsoft Shopping popped up its large notification box with a blue button that, when clicked, invokes an affiliate link and sets affiliate cookies.
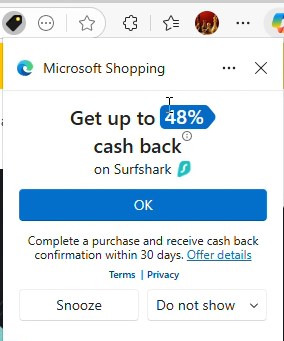
Notice the sequence: Begin at another publisher’s CJ affiliate link, merchant’s site loads, and Edge Shopping does not stand-down. This is squarely within the prohibition of CJ’s rules.
Edge sends detailed telemetry from browser to server reporting what it did, and to a large extent why. Here, Edge simultaneously reports the Surfshark URL (with cjdata=, cjevent=, aff_click_id=, utm_source=cj, and sf_cs=cj parameters each indicating a referral from CJ) (yellow) and also shouldStandDown set to 0 (denoting false/no, i.e. Edge deciding not to stand down) (green).
POST https://www.bing.com/api/shopping/v1/savings/clientRequests/handleRequest HTTP/1.1
...
{"anid":"","request_body":"{\"serviceName\":\"NotificationTriggering\",\"methodName\":\"SelectNotification\",\"requestBody\":\"{\\\"autoOpenData\\\":{\\\"extractedData\\\":{\\\"paneState\\\":{\\\"copilotVisible\\\":false,\\\"shoppingVisible\\\":false}},\\\"localData\\\":{\\\"isRebatesEnabled\\\":true,\\\"isEdgeProfileRebatesUser\\\":true,\\\"shouldStandDown\\\":0,\\\"lastShownData\\\":null,\\\"domainLevelCooldownData\\\":[],\\\"currentUrl\\\":\\\"https://surfshark.com/?cjdata=MXxOfDB8WXww&cjevent=cb8b45c0cc8e11f0814803900a1eba24&PID=101264606&aff_click_id=cb8b45c0cc8e11f0814803900a1eba24&utm_source=cj&utm_medium=6831850&sf_cs=cj&sf_cm=6831850\\\" ...
With a standard CJ affiliate link, and with multiple references to “cj” right in the URL, I struggle to see why Edge failed to realize this is another affiliate’s referral. If I were writing stand-down code, I would first watch for affiliate links (as in the first screenshot above), but surely I’d also check the landing page URL for significant strings such as source=cj. Both methods would have called for standing down.
Another notable detail in Edge’s telemetry is that by collecting the exact Surfshark landing page URL, including the PID= parameter (blue), Microsoft receives information about which other publisher’s commission it is taking. Were litigation to require Microsoft to pay damages to the publishers whose commissions it took, these records would give direct evidence about who and how much, without needing to consult affiliate network logs. This method doesn’t always work—some advertisers track affiliates only through cookies, not URL parameters; others redirect away the URL parameters in a fraction of a second. But when it works, more than half the time in my experience, it’s delightfully straightforward.
Additional observations
If I observed this problem only once, I might ignore it as an outlier. But no. Over the past three weeks, I tested a dozen-plus mainstream merchants from CJ, Rakuten Advertising, Impact, and Awin, in 25+ test sessions, all with screen recording. In each test, I began by pasting another publisher’s affiliate link into the Edge address bar. Time after time, Edge Shopping did not stand-down, and presented its offer despite the other affiliate link. Usually Edge Shopping’s offer appeared in a popup as shown above. The main variation was whether this popup appeared immediately upon my arrival at the merchant’s home page (as in the Surfshark example above), versus when I reached the shopping cart (as in the Newegg example below)s.
In a minority of instances, Edge Shopping presented its icon in Edge’s Address Bar rather than opening a popup. While this is less intrusive than a popup, it still violates the contract provisions (“non-interference”, “may not activate”, “may not operate”, may not “interfere”, all as quoted above). Turning blue to attract a user’s attention—this invites a user to open Edge Shopping and click its link, causing Microsoft to claim commission that would otherwise flow to another publisher. That’s exactly what “non-interference” rules out. “May not operate” means do nothing, not even change appear in the Address Bar. Sidenote: At Awin, uniquely, this seems to be allowed. See Publisher Code of Conduct, Rule 4, guidance 4.2. For Awin merchants, I count a violation only if Edge Shopping auto-opened its popup, not if it merely appeared in the Address Bar.
Historically, some stand-down violations were attributed to tricky redirects. A publisher might create a redirect link like https://www.nytimes.com/wirecutter/out/link/53437/186063/4/153497/?merchant=Lego which redirects (directly or via additional steps) to an affiliate link and on to the merchant (in this case, Lego). Historically, some shopping plugins had trouble recognizing an affiliate link when it occurred in the middle of a redirect chain. This was a genuine concern when first raised twenty-plus years ago (!), when Internet Explorer 6’s API limited how shopping plugins could monitor browser navigation. Two decades of improvements in browser and plugin architecture, this problem is in the past. (Plus, for better or worse, the contracts require shopping plugins to get it right—no matter the supposed difficulty.) Nonetheless, I didn’t want redirects to complicate interpretation of my findings. So all my tests used the simplest possible approach: Navigate directly to an affiliate link, as shown above. With redirects ruled out, the conclusion is straightforward: Edge Shopping ignores stand-down even in the most basic conditions.
I mentioned above that I have dozens of examples. Posting many feels excessive. But here’s a second, as to Newegg, from testing on December 5, 2025.
Litigation ongoing
Edge’s stand-down violations are particularly important because publishers have pending litigation about Edge claiming commissions that should have flowed to them. After MegaLag’s famous December 2024 video, publishers filed class action litigation against Honey, Capital One, and Microsoft. (Links open the respective dockets.)
I have no role in the case against Microsoft and haven’t been in touch with plaintiffs or their lawyers. If I had been involved, I might have written the complaint and Opposition to Motion to Dismiss differently. I would certainly have used the term “stand-down” and would have emphasized the governing contracts—facts for some reason missing from plaintiffs’ complaint.
Microsoft’s Motion to Dismiss was fully briefed as of September 2, and the court is likely to issue its decision soon.
Microsoft’s briefing emphasizes that it was the last click in each scenario plaintiffs describe, and claims that last click makes it “entitled to the purchase attribution under last-click attribution.” Microsoft ignores the stand-down requirements laid out above. Had Microsoft honored stand-down, it would have opened no popup and presented no affiliate link—so the corresponding publisher would have been the last click, and commission would have flowed as plaintiffs say it should have.
Microsoft then remarks on plaintiffs not showing a “causal chain” from Microsoft Shopping to plaintiffs losing commission, and criticizes plaintiffs’ causal analysis as “too weak.” Microsoft emphasizes the many uncertainties: customers might not purchase, other shopping plug-ins might take credit, networks might reallocate commission for some other reason. Here too, Microsoft misses the mark. Of course the world is complicated, and nothing is guaranteed. But Microsoft needed only to do what the contracts require: stand-down when another publisher already referred that user in that shopping session.
Later, Microsoft argues that its conduct cannot be tortious interference because plaintiffs did not identify what makes Microsoft’s conduct “improper.” Let me leave no doubt. As a publisher participating in affiliate networks, Microsoft was bound by networks’ contracts including the stand-down terms quoted above. Microsoft dishonored those contracts to its benefit and to publishers’ detriment, contrary to the exact purpose of those provisions and contrary to their plain language. That is the “improper” behavior which plaintiffs complain about. In a puzzling twist, Microsoft then argues that it couldn’t “reasonably know[]” about the contracts of affiliate marketing. But Microsoft didn’t need to know anything difficult or obscure; it just needed to do what it had, through contract, already promised.
Microsoft continues: “In each of Plaintiffs’ examples, a consumer must affirmatively activate Microsoft Shopping and complete a purchase for Microsoft to receive a commission, making Microsoft the rightful commission recipient if it is the last click in that consumer’s purchase journey.” It is as if Microsoft’s lawyers have never heard of stand-down. There is nothing “rightful” about Microsoft collecting a commission by presenting its affiliate link in situations prohibited by the governing contracts.
Microsoft might or might not be right that its conduct is acceptable in the abstract. But the governing contracts plainly rule out Microsoft’s tactics. In due course maybe plaintiffs will file an amended complaint, and perhaps that will take an approach closer to what I envision. In any event, whatever the complaint, Microsoft’s motion to dismiss arguments seem to me plainly wrong because Microsoft was required by contract to stand-down—and it provably did not.
***
In June 2025, news coverage remarked on Microsoft removing the coupons feature from Edge (a different shopping feature that recommended discount codes to use at checkout) and hypothesized that this removal was a response to ongoing litigation. But if Microsoft wanted to reduce its litigation exposure, removing the coupons feature wasn’t the answer. The basis of litigation isn’t that Microsoft Shopping offers (offered) coupons to users. The problem is that Microsoft Shopping presents its affiliate link when applicable contracts say it must not.
Catching affiliate abuse
I’ve been testing affiliate abuse since 2004. From 2004 to 2018, I ran an affiliate fraud consultancy, which caught all manner of abuse—including shopping plugins (what that page calls “loyalty programs”), adware, and cookie-stuffing. My work in that period included detecting the activity that led to the 2008 litigation civil and criminal charges against Brian Dunning and Shawn Hogan (a fact I can only reveal because an FBI agent’s declaration credited me). I paused this work from 2018 to 2024, but resumed it this year as Chief Scientist of Visible Performance Technologies, which provides automation to detect stand-down violations, adware, low-intention traffic, and related abuses. As you’d expect, VPT has long been reporting Edge stand-down violations to clients that contract for monitoring of shopping plugins.
My time from 2018 to 2024, as an employee of Microsoft, is relevant context. I proposed Bing Cashback and led its product management and business development through launch. Bing Cashback put affiliate links into Bing search results, letting users earn rebates without resorting to shopping plugins or reminders, and avoiding the policy complexities and contractual restrictions on affiliate software. Meanwhile, Bing Cashback provided a genuine reason for users to choose Bing over Google. Several years later, others added cashback to Edge, but I wasn’t involved in that. Later I helped improve the coupons feature in Edge Shopping. In this period, I never saw Edge Shopping violate stand-down rules.
I ended work with Bing and Edge in 2022, after which I pursued AI projects until I resigned in 2024. I don’t have inside knowledge about Edge Shopping stand-down or other aspects of Microsoft Cashback in Edge. If I had such information, I would not be able to share it. Fortunately the testing above requires no special information, and anyone with Edge and a screen-recorder can reproduce what I report.